告别通用 Exception:为何你的项目需要一套自定义异常体系?
在我们的日常编码中,try-catch 块是再熟悉不过的老朋友了。但很多时候,我们的 catch 语句里捕获的是一个宽泛的 Exception,或者是在一个方法签名上罗列着一长串 throws IOException, SQLException, TimeoutException...。
这能工作,但不够优雅,也不够健壮。当项目规模变大、团队成员增多时,混乱的异常处理会成为滋生 Bug 和增加维护成本的温床。
那么,有没有更好的方式呢?答案是肯定的:为你的应用程序或框架设计一套自定义的异常体系。
这并非什么高深莫测的技术,而是像 Spring、Hadoop、Flink 等几乎所有成熟框架都在践行的最佳实践。本文将带你了解“为什么”以及“怎么做”。
一、为什么要自定义异常体系?目的与好处
投入时间去设计看似“多余”的异常类,能为我们带来不可估量的好处。
1. 建立统一的异常“语言”
想象一下,你的应用是一个国家,自定义异常体系就是这个国家的“官方语言”。
统一捕获入口:通过定义一个共同的基类(如
MyAppException),API 的调用者可以非常方便地通过catch (MyAppException e)来捕获所有源于你应用内部的可预见异常。这极大地简化了客户端代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 没有自定义异常体系时,你需要...
try {
complexOperation();
} catch (IOException e) {
// 处理IO问题
} catch (SQLException e) {
// 处理数据库问题
} catch (InterruptedException e) {
// 处理中断问题
}
// 有了自定义异常体系后,你可以...
try {
complexOperation();
} catch (MyAppException e) {
// 优雅地处理所有源自我方应用的可预见性问题
log.error("An application-specific error occurred.", e);
// 执行通用的回滚或清理逻辑
}
2. 明确问题边界与责任
当一个异常被抛出时,它的类型就是它的“身份证”。
- 来源清晰:捕获到
NullPointerException时,问题可能是任何地方的代码不严谨。但如果捕获到的是OrderNotFoundException,你就能立刻断定:这是一个业务逻辑层面的错误,与订单相关,问题源于我们的应用,而不是底层的网络库或数据库驱动。这极大地缩小了问题排查的范围。
3. 传递丰富、有上下文的错误信息
标准的异常类所能承载的信息有限。自定义异常则可以携带任何你需要的上下文信息。
命名即文档:
PaymentGatewayException这个名字远比IOException("Payment failed")更具描述性。携带状态:我们可以为异常类添加额外的字段。例如,一个支付网关异常可以包含第三方返回的错误码和错误信息,方便精准定位。
1
2
3
4
5
6
7
8
9
10
11
12public class PaymentGatewayException extends MyAppException {
private final String gatewayErrorCode;
public PaymentGatewayException(String message, String gatewayErrorCode, Throwable cause) {
super(message, cause);
this.gatewayErrorCode = gatewayErrorCode;
}
public String getGatewayErrorCode() {
return gatewayErrorCode;
}
}
4. 设计稳定的 API
对于库或框架的作者来说,稳定的 API 契约至关重要。
- 隐藏实现细节:一个公共方法可以声明
throws MyAppException。未来,即使你内部重构,引入了新的具体异常类型(比如从DatabaseException变成了RedisCacheException),只要它们都继承自MyAppException,这个公开的 API 签名就无需改变。这保护了你的用户,避免了因内部实现变更而导致他们需要修改代码。
5. 精心区分“天灾”与“人祸”
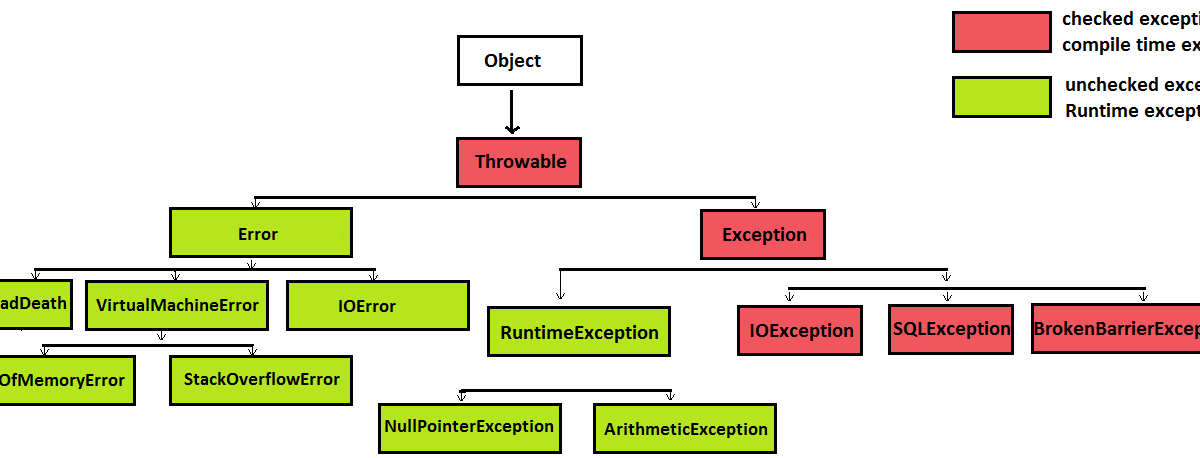
Java 的异常分为受检(Checked)和非受检(Unchecked/Runtime)。我们也应该在自己的体系中遵循这一思想。
- 受检异常 (
extends Exception):用于表示可恢复的、外部因素导致的错误。比如网络中断、文件不存在。API 的调用者应该被强制处理这类问题,因为它们是可预见的。我们通常会定义一个MyAppException作为这类异常的基类。 - 非受检异常 (
extends RuntimeException):用于表示程序缺陷(Bug)或不可恢复的系统级错误。比如,一个本不该为 null 的对象却是 null,或者一个非法的状态转换。对于这类问题,我们通常不希望调用者捕获它,而是让程序“快速失败”,暴露 Bug。我们可以定义一个MyAppRuntimeException作为这类异常的基类。
二、如何构建自己的异常体系:三步走
构建过程非常简单,我们以一个假想的电商系统为例。
第一步:定义根异常
首先,为受检异常和非受检异常分别创建一个基类。这为整个体系提供了统一的根。
1 | // 1. 自定义受检异常的基类 |
第二步:创建具体的业务异常
基于根异常,派生出能够描述具体业务场景的子类。
1 | // 用户查询时,未找到对应订单,这是一个可预见的业务异常 |
第三步:在代码中使用它们
现在,在你的业务逻辑中抛出这些精确的异常,并在调用处进行优雅地处理。
1 | // ---- 在业务逻辑层 ---- |
三、真实世界案例:Flink 的异常设计
Apache Flink 作为顶级分布式计算框架,其异常体系是教科书般的典范。
org.apache.flink.util.FlinkException: 这是 Flink 所有受检异常的根。当你提交一个作业、触发一个 Savepoint 或查询一个不存在的作业时,都可能遇到它的子类,如:JobNotFoundException:清晰地告诉你作业不存在。CheckpointException:说明 Checkpoint 过程出错了。RpcConnectionException: 表明与 JobManager 或 TaskManager 的 RPC 通信失败。
org.apache.flink.util.FlinkRuntimeException: 这是 Flink 所有非受检异常的根。通常用于指示框架内部的断言失败或严重的、不可恢复的配置错误。
这种设计使得 Flink 的用户可以编写出非常稳健的代码:
1 | try { |
结论
为你的项目构建一套自定义异常体系,并不是“过度设计”,而是对代码质量、可维护性和团队协作效率的一项明智投资。它能帮助我们:
- 结构化地管理错误。
- 清晰化地定位问题。
- 简单化地处理异常。
- 稳定化地迭代 API。
下次当你再启动一个新项目,或者重构一个旧模块时,不妨花点时间思考一下它的异常处理策略。从定义一个 MyAppException 基类开始,你将踏上构建更健壮、更优雅软件的道路。你的未来,以及你未来的同事,都会为此感激你。
告别通用 Exception:为何你的项目需要一套自定义异常体系?